
LLM vs SLM: OPTIMIZING YOUR INFERENCING SOLUTION FOR GENERATIVE AI
Uncover the key distinctions between Large Language Models and Small Language Models, and how they influence the selection of the most efficient AI inference architecture for your AI data center.
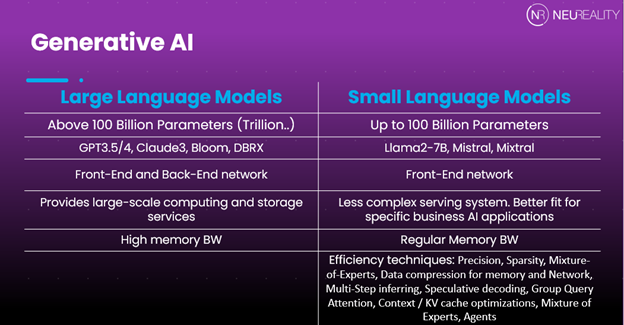
Understanding LLMs and SLMs
Language Models (LMs) play a crucial role in various AI applications, including natural language processing (NLP) and machine translation. LLMs, or Large Language Models, refer to models that have a significantly larger number of parameters compared to traditional language models. These models are designed to handle complex language tasks and provide highly accurate results.
On the other hand, Small Language Models (SLMs) are more compact versions of LLMs. These models have fewer parameters but are still capable of performing various language-related tasks, albeit with slightly reduced accuracy.
Understanding the distinctions between LLMs and SLMs is essential when choosing the right AI inference architecture for your data center. The size and complexity of the language model significantly impact the overall performance, cost efficiency, and energy consumption of the AI inferencing system. When it comes to the daily operation of your AI application – inferencing – your business success and ROI depend on cost management and profit margins (not high performance at any cost).
Affordable AI Inferencing = Biggest Barrier
Take smart cities, for instance. Municipalities like New York or San Francisco often lack the budget to process all the video streams for applications such as theft prevention or traffic management. To make AI viable in such scenarios, it’s clear that a one-size-fits-all approach to AI infrastructure doesn’t work.
Google’s early assumption that a TPU (Tensor Processing Unit) cluster could serve all purposes – even AI inferencing servers – is now outdated. Today’s challenge in AI inferencing is affordability. Without affordable intelligence, the market will remain stuck at a low 25-35 percent business adoption rate.
Frankly, the AI industry has hit a hall where raw performance overpowers affordability. 2024 is the time for AI pioneers and innovators to urgently shift focus from AI training to AI inference. Together, we can make large-scale AI data center deployments far more affordable for governments and businesses outside of BigTech to take full advantage of all the amazing new capabilities – from Multimodality and Mixture of Experts from DALL-E to Retrieval-Augmented Generation (RAG) to Anthropic’s Claude-3.
Factors to Consider when Choosing AI Inference Architecture
At the recent AI Accelerator Summit in San Jose, CEO Moshe Tanache shared a simple comparison chart – getting engineers and technologists to think differently about the affordability challenge of Generative AI deployment. Examples: 1) designing smaller trained AI models; 2) finding ways to break LLMs down in data center deployment to not exceed the average power limitations of a bank, insurance, healthcare, big box retailer or smart city.
When selecting an AI inference architecture, several factors must be considered to ensure optimal performance and cost efficiency:
The specific requirements of your AI applications
Different applications may have varying demands in terms of model size, response time, and accuracy. Understanding these requirements is crucial in selecting the appropriate inference architecture.
Scalability
The ability to scale the AI inferencing system to handle increasing workloads is essential. Consider the potential growth of your AI applications and choose an architecture that can accommodate future demands.
Hardware compatibility
Ensure that the chosen AI inferencing solution is compatible with hardware available now or in the future for your AI data center. This includes GPUs, accelerators, and other specialized hardware That said, all accelerators rely upon CPU-centric today and it’s proving to be one of the biggest culprits in AI inferencing. More on that later.
Cost-effectiveness
Balancing the cost of the inference architecture with the desired performance and accuracy is crucial. Optimize the architecture to minimize unnecessary expenses without compromising the quality of results.
Considering these factors today – and in advance of your LLM and SLM deployments – helps businesses make an informed decision when choosing the best AI inference solution without overspending on GPUs which are already underutilized in today’s CPU-centric architecture.
Performance Comparison between LLMs and SLMs
LLMs and SLMs differ in terms of performance due to their varying sizes and complexities. While LLMs excel in handling complex language tasks with high accuracy, SLMs offer a more lightweight solution with slightly reduced accuracy.
The performance comparison depends on the specific use case and requirements of your AI applications. In some scenarios, the accuracy provided by LLMs may be necessary; while in others, the efficiency and speed of SLMs might be more important.
Mistral-7B, with 7 billion parameters, is a highly efficient SLM. OpenAI’s GPT-2 with 1.5 billion parameters fits comfortably within the SLM category and demonstrates the feasibility of smaller, more efficient models.
In contrast, Google’s PaLM (Pathways Language Model), with 540 billion parameters, represents the high complexity and resource demand of an LLM. Some fit in the middle too, including EleutherAI’s GPT-NeoX-20B consisting of 20 billion parameters which bridges the gap between SLMs and LLMs, and provides a balanced approach to complexity and efficiency.
Cost Efficiency and Energy Consumption Analysis
Due to their smaller size and simplified architecture, SLMs require fewer computational resources, resulting in lower costs and energy consumption. Performing a thorough cost efficiency and energy consumption analysis of each Language Model option is crucial in determining the optimal AI inference architecture for your data center.
Aside from SLM’s lower energy consumption and cost, AI data center operators can also reduce the hardware cost associated with overbuying expensive GPUs and other AI accelerators underutilized for their specific tasks. This optimization helps avoid using a ‘hammer for a thumbtack,’ ensuring that the resources are efficiently utilized for the given workload.
boosting AI AcceleratorS for AI Inferencing
To further enhance the efficiency and performance of your AI inferencing system, consider how much you’re getting out of your current AI accelerators such as GPUs. How much of the time are they idle or underused due to CPU performance bottlenecks? By carefully analyzing the workload and requirements of your AI applications, start allocating the right amount of computational resources to each task to minimize silicon waste – which averages 30-40% utilization today.
Employing techniques like model quantization and compression can further optimize AI accelerator utilization and reduce your overall hardware requirements.
We recently published our inaugural real-world Performance Results, demonstrating that paired with any GPU or AI accelerator the NR1-S boosts total output – and achieves 100% linear scalability while reducing energy consumption.
Optimizing AI inference is about balancing your application’s needs with your data center’s capabilities. Our NR1-S outperforms traditional CPU-centric architectures, which all of today’s GPUs and AI accelerators rely on. These old systems were never designed for AI’s compute and power demands, which is why organizations like OpenAI have experienced exorbitant costs and why AI data centers are seeing a growing energy crisis. That trend will only continue unless we as an AI tech industry come together and choose a more sustainable path.
Out with the Old, In with the NR1-S
NR1-S offers that more affordable, environmentally friendly, and scalable AI inference solution. The time is now, and so is a viable solution. You will want a leaner AI inference infrastructure in place before deploying high-volume, high-variety GenAI pipelines.
In Q3, NeuReality is launching Generative AI performance tests in real-world scenarios. This is your chance to compare any LLM, SLM, or RAG application on a CPU-reliant GPU or AI accelerator versus NR1-S.
Sign up now to participate in Israel lab testing or run a Proof of Concept on your site. Together, we make your AI data centers more affordable and reduce your carbon footprint. Be part of the solution for a sustainable and cost-effective AI future as Generative AI continues to grow and evolve!
Contact us at hello@neureality.ai.